
什么是数据湖?
邮箱里看到了技术文章推送的邮件,提到了数据湖、湖仓一体等等概念,我有点好奇到底是什么东西。
初步看了两篇文章,我感觉,这个“数据湖”又是一个热门潮流概念吧。没想到 Martin Fowler 大叔也撰文专门描写了数据湖。
邮箱里看到了技术文章推送的邮件,提到了数据湖、湖仓一体等等概念,我有点好奇到底是什么东西。
初步看了两篇文章,我感觉,这个“数据湖”又是一个热门潮流概念吧。没想到 Martin Fowler 大叔也撰文专门描写了数据湖。
“回溯法”(Backtracking)和“深度优先搜索”(Depth First Search-DFS),看起来名字截然不同,字面意思也没什么相似的,不过,如果你经常刷题,渐渐就不免会注意到这个问题。为什么这两者会凑到一起去了?
我最早注意到这个问题,是观看题解的示范代码,示范代码是一道使用“回溯法”解决的题目,可是很奇怪,函数却并命名为 dfs,明明是回溯法,怎么用 dfs 来命名函数呢?为啥不用 backtracking 命名函数呢?
Backtracking is a general algorithm for finding all (or some) solutions to some computational problems, notably constraint satisfaction problems, that incrementally builds candidates to the solutions, and abandons a candidate (“backtracks”) as soon as it determines that the candidate cannot possibly be completed to a valid solution.
回溯法是一种通用的算法,用于找到一些计算问题所有的(或者部分的)解,尤其是约束满足类问题,该算法逐渐构建潜在的解,一旦确认潜在的解无法满足,则立刻抛弃。
回溯法一个最经典的例题是“八皇后”问题,在一个国际象棋棋盘上,尝试放 8 个皇后,这 8 个皇后不能互相攻击,尝试找到一种或所有的解。8 个皇后不能在在同一行,同一列,或者同一对角线上。
回溯法解题的步骤大概是,首先在第一行挑选一个位置防止一个皇后,然后在第二行,放置皇后的时候,就不能产生攻击,一旦发现第 8 个皇后已经放置完毕,则搜索到了一个解。如果还没有放足 8 个,就发现已经无处可以放置了,则返回上一行,将上一行的皇后换一个位置放置(回溯)。
Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures. The algorithm starts at the root node (selecting some arbitrary node as the root node in the case of a graph) and explores as far as possible along each branch before backtracking.
深度优先搜索,是一种用于遍历或者搜索树或者图数据结构的算法。算法从树的根节点开始(或者图的任意节点),然后沿着连接节点的边,尽可能深的遍历图,直到回溯。
在深度优先遍历的定义里,出现了回溯这个词。不难想象,假设有一颗树,我们从根节点开始深度优先遍历,那么会从根节点,一直向下深入,直到叶子节点,这时候如果想继续遍历,则必须返回父节点,这样才能寻找兄弟节点进行遍历。这个“返回” 的过程,就根回溯极其类似。
结合维基百科的定义和两个算法的基本描述,我们不难发现这两个算法的相同之处,通俗点说,都是选定一种策略,一条路走到黑,如果走入死路,就退回来,重新选择。
这“两种”算法的另一个相同之处是,都是遍历解空间的一种策略,说直白点,都是“穷举”的算法,只不过,穷举解空间也好,穷举图也好,都需要选定一个策略,才能没有遗漏和没有重复的完成穷举。
所以,我自己更倾向于认为,这两者,其实是同一种算法,只是从不同角度出发去称呼他们。事实上,我打开了好几本中文版算法书,《算法 4》,《算法导论》之类的,《算法竞赛入门经典》《算法竞赛进阶指南》等等,几乎就没找到过关于“回溯法” 的介绍和定义。难怪那些搞竞赛的,遇到回溯法,都会用 dfs 去命名函数。
通过在 StackOverflow 搜索,还真有人问这个问题。
For me, the difference between backtracking and DFS is that backtracking handles an implicit tree and DFS deals with an explicit one. This seems trivial, but it means a lot. When the search space of a problem is visited by backtracking, the implicit tree gets traversed and pruned in the middle of it. Yet for DFS, the tree/graph it deals with is explicitly constructed and unacceptable cases have already been thrown, i.e. pruned, away before any search is done.
So, backtracking is DFS for implicit tree, while DFS is backtracking without pruning.
这个回答认为,回溯法,处理了隐式树,而 DFS 则处理显示的树。这看起来平凡,但是也意味深长。当使用回溯法遍历一个问题的搜索空间时,隐式树在遍历的过程中,进行剪枝。但是,DFS 算法则不同,显示的树或者图已经被构造出来了,那些不可达的节点,或者不可能的情况,此时已经被排除在外了,只要按部就班全部遍历即可。所以,他认为,回溯法就是隐式树/图的深度优先搜索,而 DFS 就是没有剪枝的回溯法。
当然,也有很多回答认为是两种不同的算法,只是我比较倾向于这个答案。也有从字面去解释的,我觉得也可以听听,比如有人说,回溯法是解决问题的方法论,而 DFS 是算法。隐式图,显示图什么的,也不那么难以理解。事实上,我认为现实世界里,只有隐式图,真正的显示图是很罕见的。正因为我们对现实世界进行了抽象,才出现了显示图这种东西。
比如,使用回溯法常见的一类问题就是排列组合问题。例如经典的,使用 n 对括号,能排列出多少种合法的括号串(括号必须配对)。这是经典的需要回溯法解决的问题,你能把这个问题想象成图么?不管如何,如果你能把这个问题写成一个递归函数来解决,至少在递归深入到下一层和回来的过程,都绘制成节点和边的话,这个可视化出来的东西,就是一棵树(树是图的特例)。
所以,不用在纠结“深度优先搜索”和“回溯法”有什么区别了,只要知道,这两者就是一体两面,或者你认为根本是一回事也不为过。显示图和隐式图也没任何区别。只是隐式图更贴近显示世界,而显示图更贴近抽象世界。如此而已。
刷题到现在,不知不觉过了 500 大关后,真的不能再随随便便了,要认真起来了。就好像写博客,坚持了几年后,你就不自觉地内化了这个行为,好像自己隔了一段日子,就一定要写点什么了。
之前 500 纪念的文章里,也说了,明确感受到了瓶颈。好像自己刷题没什么长进了。幸好一个朋友提点,要逐个点击破来提高了。这两天就开始留意了。方法很简单,就是之前不会做就跳过的东西,现在就要求自己一定要看懂,不能随便跳过任何东西。不惜代价也要搞明白再往后。就发现,其实自己掌握的东西还是千疮百孔的。
其实目标是最重要的东西,就是到底想通过刷题获得什么?这样才能决定做法。如果说,刷题是为了找工作,应该刷《剑指》,反反复复刷,知道随机跳题都能秒做对。当然,这不是我的目标,因为之前也说了,35+ 找工作的时候,刷题只是获得一个聊天的机会,并不能帮助我了。
我现在定个小目标是,能在周赛妥妥 3 道题。很多同学可能觉得这很容易,当然我打心眼里也没觉得有多难,所以只能是一个小目标了。只是,以此为目标的时候,我能清晰定位到,自己缺少多少知识。也是自己之前可以忽略的东西。
当然,短板还是有很多很多的,只是这几个是我目前想到的,欠缺比较多的东西,如果有针对性地训练的话,可能会有比较大的成效,也即在这些领域投入,边际效益会大一点。那就把这几个定成这一轮的焦点问题,尝试比较集中去投入一些经历。
目前,在参加一个 91 天学算法训练营,花了 10 块的,群里的人感觉比较基础,自理能力也一般,经常还在问群主一些网站登录不了怎么办的问题,GitHub 没法访问的问题。每天的题目按照数据结构的顺序在出,不过呢,几乎都没有挑战了,打算就做着每日打卡权当是查漏补缺了。
LC 的每日打卡还是要坚持打的,因为几乎可以认为是随机在跳题出来的,这样比较容易发现自己的短板的。
此外,还是应该找专题来做,集中攻破一个个点。然后,三到六个月来回顾。
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。
- 最长递增子序列 <-- 传送门
这道题目是一道非常经典的基础算法题。
一个数组里包含多少个子序列呢?按照数组原有的顺序,每个元素我们可以选择删除或者保留,最后形成的序列,就是一个子序列。每个位置有“删除”或“保留” 2 种情况,所以,穷举的话,总共有 2^n 个子序列。
这些子序列的长度,从 0 到 n 不等,我们现在想求出,子序列中元素严格递增的序列,最长的长度是多少。不难得到,最短的严格递增子序列长度是 1,最长的可能性是 n。也同样不难想象,某一个长度的严格递增子序列,不止一条。
我们尝试使用递归法,来设计一个算法,求解这道题。下面是推理过程:
步骤 1,递归假设。我们直接假设,可以求出长度为 n 的数组的最长递增子序列的长度,也即最终答案,用 f(n) 表示。
在这个基础上,我们来考察第 n + 1 个数,我们能否使用 f(n) 计算出来。一个数字能不能让一个递增序列的长度 +1,取决于这个数字是否大于序列中最大的数字(因为是要保持数组的原有顺序,不用考虑这个数字是否小于最小值的情况)。现有递归假设,不包含那个最大值,所以假设失败。
增强假设。我们除了能计算出最长子序列的长度,我们还能计算这个子序列的最大值。考虑到,同样长度的子序列很多个,那么这么多子序列的最大值,我们返回哪个呢?稍加思考,发现,我们可以返回这里最小的一个,记为 Xs。因为新来一个数字,只要比 Xs 大,就可以让最长子序列的长度 +1 了。
在新的假设基础上,我们考察第 n + 1 个数,如果这个数字大于 Xs,那么 f(n+1) 的最长子序列,就是 f(n) 的最长长度 +1。那么,新的最长子序列的最大值是多少呢?显然也是第 n + 1 个数。可是如果第 n + 1 个数,小于 Xs 怎么办?假如 f(n) 计算的最长子序列长度是 L,最大值是 Xs,第 n + 1 个数字小于 Xs,但是比长度 L-1 的子序列的最大值要大,就可以得到另一条长度 L 的子序列,那条子序列的最大值是第 n + 1 个数,这种情况,需要更新 Xs 为第 n + 1 个数。那还是同样的问题,如果小于又怎么办呢?还要用同样的办法再向前探索 L-2 的子序列最大值。
这一部分稍微有点点抽象,但是细想一下不难理解的。所以,我们目前的假设,还是不够强。
继续增强假设。假设我们能计算出,长度从 1 到 L 的每种长度的子序列的最大值(里面的最小的一个)。
在这个最新的假设下,考察第 n + 1 个数。通过第 n + 1 个数与整个数组的每一个数,从后往前逐个判断,就能决定是追加到最后面,还是替换其中的一个。不难证明,返回的这 L 个数字,是从小到大严格递增的(所以可以用二分法找到替换的位置)。最后这个数组的长度 L 正是最后的答案。
基于上面的推理,我们写出递归算法:1
2
3
4
5
6
7
8
9
10
11
12
13class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
def lis(i: int) -> List[int]:
if i == 0: return [nums[i]]
res = lis(i - 1)
# 以下使用二分法,确认替换的位置
j = bisect.bisect_left(res, nums[i])
if j == len(res): # 比最大的还大,就追加到末尾
return res + [nums[i]]
else: # 否则就替换
res[j] = nums[i]
return res
return len(lis(len(nums) - 1)
算法复杂度分析,每一轮递归里,问题规模减小 1,总递归 n 层,并且每层进行了一次二分查找。所以总时间复杂度是 O(n logn)。空间复杂度是 O(n)。
通过递归假设和不断增强假设,我们设计出了递归算法来求解最长递增子序列。这道题也可以很轻松写成迭代的写法,请读者自己动手完成。
当然,这也是一道典型的动态规划的题型,可以用动态规划来求解。假设我们可以设状态为以第 i 个数字结尾的最长子序列,长度为 Li。对于第 i + 1个数字,我们可以检查每个数字 i ,如果大于它,新子序列的长度 Li + 1,这里的最大值就是以第 i + 1 个数字结尾的最长递增子序列长度。
因为,最长子序列不一定是以哪个值结尾的,所以最后整个 dp 数组的最大值就是最终答案。
写出代码就是:1
2
3
4
5
6
7
8class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
dp = [1] * len(nums) # 不难想象,最短的递增子序列长度是 1,当作初始值
for i in range(1, len(nums)):
for j in range(i):
if nums[i] > nums[j]:
dp[i] = max(dp[i], dp[j] + 1)
return max(dp)
该算法的时间复杂度是 O(n^2),因为每个数字,我们都要考察前面所有的数字的情况。空间复杂度是 O(n)。
– END –
又有许久不曾写过题解了,题目一直还在做着,就是懒得写题解,主要最近家里事有点让我烦心,心绪不宁无法安心写作。今天我猛然一看,统计数字 498 了,赶快找两道简单水题,凑个整,算是突破了 500 大关。当然,这对我个人来说,或者毫无意义,总是一个付出的明证吧。
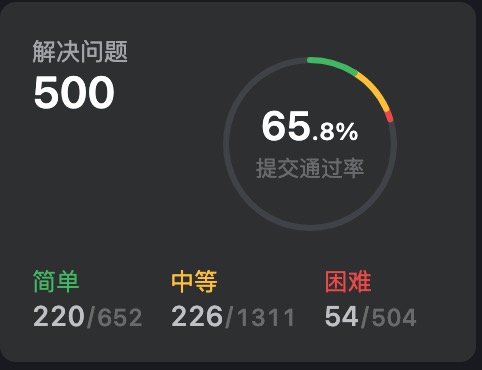
LeetCode 刷题统计
从做题结构看,还是简单题偏多,你就可以想见,这个数字还是挺水的。含金量不像数字那么敦实。花了多久做了这么多题目呢?大概可以认为是 8 个月多吧。

LeetCode 打卡热力图
其实第一次尝试刷题是 2020 年 8 月开始,只在工作日,每天做 1 道,这样坚持了一个半月,放弃了,当时刷了 100 多道吧。今年的 2 月,又开始第 2 波了,上次使用 Go 刷的,这次是用 Python 刷的。两次都重开了做题计划,所以,第二次其实是把第一次的题都又做了一遍的。即这 500 题有 100 多道我是用 Go 做过一遍的。
刷题大体来说还是快乐的,因为简单。这话不是凡尔赛,真实的个人体会。题目都是那么纯粹,有些题甚至是为了做题而出题,就更显得纯粹。你不懂的时候,可能会让你暴躁得抓头发,那只能是你的见识太少了。因为这些题并不难,只是没见过而已。
比起生活中遇到的那些无解的困难,比起工作上的这些困境。刷题相比之下只是一个纯粹而快乐的过程。刷题不能解决我的问题,但是可以让我从痛苦的生活中逃离一小会儿,用能获得的进步给自己一点点安慰。我想这和那些沉溺在游戏里打怪的人没有太多的区别,只是这个上瘾程度有限。
我加过各种群,自己也有个小群,都是大家一起刷题的。大部分人比我年轻 10 岁以上。对他们来说,刷题是很实在的,因为现在找工作,想去个好点的公司,都要考算法题的。刷题最大的好处是,让大家有所准备,能够胜任 Code Challenge,获得心仪的 offer,确实还是有效的。
于我而言,只是增加了我的些许自信。毕竟刷题不是面试的全部。对我来说,更大的好处是,增加了我日常工作中解决难题的信心。我们都知道,工作中可能没有算法题,不过工作中可能会有很多很麻烦的场景。那不是说问题多困难,就是十分麻烦,我感觉刷题训练让我更加耐烦。
会让你写麻烦烧脑,容易写错,难于调试的场景时候,更有信心一点,即使写不出来,也不会气恼,删掉重写就是,这种打击在刷题的过程中早已习惯了。
没有太好的。很多同学分享经验我都看了。有几个,我觉得挺认同。刷题呢,不要纠结于非要自己做出来,刚开始很多同学就会沉溺在这个误区里。看题解不丢人。其实这是非常重要的一点,很多人比如我,很晚才领悟这一点。
刷题呢,专项密集训练效果是不错的,就是把相近题,相同考点的题,堆在一起,一顿猛刷,这样效果好。一个主题完了,再去下一个主题。不是随机拉个单子刷,那样效果不好。举个不恰当的例子吧,比如你去健身房健身。你可能会看到眼花缭乱的器械。不过你请过教练,你就会发现,那么多器械,只是少量几个跟你有关。你每次去用的器械不会超过三种。这次去,深蹲,腿弯举,腿屈伸,倒登机。全部虐腿。下次去了,高位下拉,悍马机,引体,全是虐背。刷题也差不多,这个礼拜全是位运算,下个礼拜全是动态规划。
刷题呢,也会倦怠,需要休息。我第一轮刷题,什么都不懂的,就天天随机做,当时不懂回溯,就死磕了几天回溯,连续做了十几道,然后有点感觉了。第二轮刷题,隔了三四个月多吧,我发现但凡看到题目可能可以用回溯解的,我似乎都有点感觉,写个回溯也自然了许多。可见知识技巧,需要沉淀和发酵,有时候你需要的时间地积淀。一顿猛学后,休息几个月,捡起来,反倒觉得似乎脑袋更清楚了。
刷题呢,反复做相同的题目也是有效果的。比如,你看我做了 500 题,其实这里,很多题是做了不止一遍的,其中有一道题,我看到自己有 7 次正确的提交,都在不同的日期里。有不少同学分享经验,按照一些榜单去刷,比如 Hot 100 列表啊,Top 200 列表啊什么的。还有学习专区,有很多专项,动态规划,二分法,堆等等,专项里和列表里,重复其实很高的。但是你重复做也不用担心的,你再次遇到的时候,还真的未必会做的。我们掌握的知识可能没有自己想象的那么扎实。一些很基础的题目条件反射秒写对后,你才能在一些复杂的场景下,水到渠成写出来。再举个不恰当的例子就是,你盖房子的时候,砖块水泥沙子钢筋,最后房子塌了,你怎么确定砖块的问题,还是钢筋的问题,还是你房子结构设计的问题?谁的错?最后可能是沙子用得不够。所以反复做一些基础题,做到倒背入流随手就来,你就知道你的房子砖块水泥都没问题,就是结构不对。能帮你快速排除一些错误的猜测。
很遗憾,我还是水平很低的,就好像上面说的,我刷题的结构里,太多简单题了。就是灌水成分大了点。我现在的水平就是简单题,大多数可以想出来,中等题,我大概 70% 把握,困难题,我大概 40% 把握,也即一多半做不出。
前天晚上周六,正好没有双周赛,我就开了个模拟周赛试试。最后 1 个半小时的时候,我做对了两道。又加了 5 分钟,终于第三道做出来了。第四道我都没读题目,时间耗完了。我历史上参加过 9 次周赛,6 次我做出来 2 道,2次只做出来 1 道,还有 1 次做出来 3 道,高兴坏了,那次也是我最后一次参加周赛。
刷题是需要长期坚持的,跟健身又很像,你一顿操作猛如虎,一看效果二百五。还不如细水长流,常年坚持。可能不需要很卖力,就是时不时练练,可以保持健康。在市场不断内卷的当下,保持头脑健康是很重要的。
现在我的水平已经进入瓶颈,每天这么做着也没啥长进。朋友说,你需要画个脑图一个点一个点细细去补那些漏洞了(数据结构和基础算法的漏洞,故意忽略的那些知识点),另外以前不曾踏足的领域也要逐步尝试,拓宽面,这样才可能在竞赛里做出好成绩。总之,是进入了一个边际效益很低的区段了。后续怎么做,还是要看自己的目的,想通过刷题得到什么。
– END –
好久没有写做题日记了,今天这题目有点意思,我做得蛮开心的。
这里有 n 门不同的在线课程,按从 1 到 n 编号。给你一个数组 courses ,其中 courses[i] = [durationi, lastDayi] 表示第 i 门课将会 持续 上 durationi 天课,并且必须在不晚于 lastDayi 的时候完成。
你的学期从第 1 天开始。且不能同时修读两门及两门以上的课程。
返回你最多可以修读的课程数目。
- 课程表III —> 传送门
这个题目意思看得挺绕的。举个生活中的例子来说明这个意思,就比如,你买了一张游戏点卡,一旦激活每天扣 1 点,一共 30 点,但是半年内必须用完。于是,你得到的 [durationi, lastDayi] 是什么呢?[30, 180]。
这里有个显而易见的事情,如果 durationi > lastDayi,那么就是一个不可能值,durationi 不能被消耗完。你买个 30 天的游戏点卡,但是 2 天内必须用完,所以就是你不可能用完。因为两天你只能用掉 2 点。所以,我们做题的时候,只要挑那些 durationi <= lastDayi 的数组就可以了。如果没有满足的数组,那么可以直接返回 0。
接下来就开始思考,怎么挑课了。其实,你要这么想,既然 durationi <= lastDayi 那就说明,每上一门课,都会剩余一些时间,才能到 lastDay,最少会剩余 0 天,一般都或多或少会剩一些。上得课越多,攒得日子越多,越不容易突破 lastDay。那么最简单的做法,就是把所有数组按照 lastDayi 的大小,排序即可。然后,我们用一个变量记录上过一门课后,消耗的日子,如果当前课程消耗的天数,加上消耗的总天数,没有超过 lastDayi,那么就可以修此门课。否则就不行。
可以想见,在lastDayi 相同的课程里,我们上 durationi 持续天数最短的课程,比较有利后面上更多课,于是我们可以把 lastDayi 相同的课程,按照 durationi 顺序排序。优先选择持续天数比较小的课。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution:
def scheduleCourse(self, courses: List[List[int]]) -> int:
def cmp(a: List[int], b: List[int]):
if a[1] < b[1]:
return -1
if a[1] == b[1]:
if a[0] < b[0]:
return -1
elif a[0] > b[0]:
return 1
return 0
courses = sorted([c for c in courses if c[0] <= c[1]], key = functools.cmp_to_key(cmp))
if not courses:
return 0
days = 0
count = 0
for c in courses:
if days + c[0] <= c[1]:
days += c[0]
count += 1
return count
这是我实现的算法,主体是一个排序。另外,过滤掉 durationi > lastDayi 的不可能数组。这个算法我提交后,97 个用例 过了 80 个。遇到这样一个用例:[[5,5],[4,6],[2,6]],没能通过。
这里我们看到,第一个课,正好把日子用完了,用我的算法再往后,都不能选了。但是这里很凑巧的是,假如我们第一个课不选,正好选后两个课,反而可以多修一门课。
我就意识到了问题,我知道我肯定在一个正确的方向上。只是忽略了一个问题。对于这个没能通过的用例,我们来看看问题在哪里。其实,给出的三门课里,如果我们只选一门课,那么选哪门课更有利呢?显然选持续时间最短的课比较有优势。但是因为我们按照 lastDayi 排序,则我们一定会先遇到 [5,5] 这门课。假如我们已经选了 [5,5] 这门课,那么当我们遇到 [2,6] 这门课,那么如果我们选择把 [5,5] 这门课替换成 [2,6] 这么课,结果是一样的,还是只修一门课,但是后续看到 [4,6] 这门课时候,就会得到不同的答案了。
所以,这里,我们进行这样的优化,还按照刚才的算法,如果我们遇到一门新课,但是总消耗的时间已经超过了,但是新遇到的课比已经选的课消耗时间短,我们就把已经选的课里消耗时间最长的课替换成新遇到的课,这样我们消耗的总时间显然会下降,但是我们选的课的门数却没有变化。这个替换,会优化出更多的空余时间,有可能容纳更多的课程进来。如此,可能得到更优的结果。
我们可以用最大堆来实现这个功能,每次新遇到一门课,如果可以选课,我们就选,如果不能选,就把已经选中的课里,消耗时间最长的课替换成消耗时间更短的课,这样可以在不减少选课数量的同时,空出更多时间来选新课。这样就能得到最终可选的最大课程数。实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class Solution:
def scheduleCourse(self, courses: List[List[int]]) -> int:
def cmp(a: List[int], b: List[int]):
if a[1] < b[1]:
return -1
if a[1] == b[1]:
if a[0] < b[0]:
return -1
elif a[0] > b[0]:
return 1
return 0
courses = sorted([c for c in courses if c[0] <= c[1]], key = functools.cmp_to_key(cmp))
if not courses:
return 0
days = 0
count = 0
q = []
for c in courses:
if days + c[0] <= c[1]:
days += c[0]
count += 1
heapq.heappush(q, -c[0])
elif q and -q[0] > c[0]:
days += q[0] + c[0]
heapq.heappop(q)
heapq.heappush(q, -c[0])
return count
以上是我实现的代码,因为 Python 只有最小堆,所以要加个负号不要忘记。
–END–
做算法题,不紧张是不可能的 —— Charles
给你一个字符串 s 和一个字符串列表 wordDict 作为字典,判定 s 是否可以由空格拆分为一个或多个在字典中出现的单词。
说明:拆分时可以重复使用字典中的单词。
示例 1:
输入: s = “leetcode”, wordDict = [“leet”, “code”]
输出: true
解释: 返回 true 因为 “leetcode” 可以被拆分成 “leet code”。提示:
1 <= s.length <= 300
1 <= wordDict.length <= 1000
1 <= wordDict[i].length <= 20
s 和 wordDict[i] 仅有小写英文字母组成
wordDict 中的所有字符串 互不相同
- 单词拆分 —— 传送门
题目如上,我没有都贴出来,省略了两个例子,太长了,凑合看吧。意思就是给你一个字符串集合,看看能不能刚好用集合中的词拼出给定的字符串。
解这道题目,我的想法还是先穷举,无论任何题目,其实都是穷举法,你首先要想出至少一种的穷举办法。当然你想出来的未必是最终用的方法,但是你至少想出一种。有了一个正确的穷举,你才可以谈论如何在上面优化。
这个题目让人迷惑在什么地方,我们可以用一个单词来分割这个字符串,例如,我们用 a 将 bab 这个串分割为两个 b,如果 b 在给定的字典里,那么就是可以拆分。但是因为目标串里的字母可以重复,所以,word 出现的边界不好确定,如果选错了边界,就会导致两侧不能继续被拆分。
这里其实有个问题,就是我们为什么会想到从中间拆分这个串呢?因为我们是按顺序遍历字典的。所以,字典里的第一个串,不一定出现在目标串的哪个位置。更一般的,我们会想到是从中间的某个地方去分割这个串。其实这是一个误区,因为从中间将串分为两截,前后两截也并不好处理,而且中间的位置,这个中间也是模糊的。
简化的想法其实是控制一头,我们总是去掉一个前缀,或者去掉一个后缀,如果剩下和还能用原来的字典拆分,则整个串可以被拆分。如果选错了前后缀,我们就换一个。这么一来,这就成了一个显然的递归算法。我们把目标串能否拆分,替换了目标串的前后缀能否拆分这样一个子问题。1
2
3
4
5
6
7
8
9
10
11def wordBreak(self, s: str, wordDict: List[str]) -> bool:
n = len(s)
def dfs(st: int):
if st == n: return True
for w in wordDict:
if s.startswith(w, st):
res = dfs(st + len(w))
if res: return True
return False
return dfs(0)
设计一个递归算法的方法,其实就是假设我们已经设计出了这个算法。
假设,我们得到了一个算法,这个算法可以判定目标串从 st 开始的后缀能不能被字典拆分。显然,从 len(s) 也就是目标串的长度开始的后缀,长度是 0 ,一定是可以被拆分的。剩下,我们只要遍历字典,去掉一个以字典中的词前缀后,用递归方法判定后缀就可以了。
如果是高手很容易看出来,我当时设计算法的时候,不是用上述的想法,上述的想法是我后来编的。当然,能直接这么想出来,也没什么不自然。我设计算法的时候,是用另一个方法,就是回溯法,而回溯法和 dfs 又往往是千丝万缕,当然不完全是一回事,不过写多了就喜欢这么命名了。
从回溯法出发的思路也可以解释一下,就是从目标串的 st 下标开始搜索,如果可以成功扩展一个前缀,就深入一层,从 st + len(word) 这个下标开始,用相同的方法继续向前探索,如果探索失败就回退到 st,如果探索成功就直接返回。听起来是不是也有点像深度优先搜索呢?所以我总喜欢用 dfs 来命名回溯的方法名。
结合题目的规模提示,我们可以分析一下这个算法的时间复杂度,递归的每一层,分支数量是字典的长度 m,单词的长度是 n,时间复杂度是 O(m^n),不超过 1000^300也就是 10^900。这是一个天文数字。当然,因为字典里每个词都是不同的,所以实际拆分没那么恐怖,但是你不用侥幸,肯定在那个量级。
考虑到我们设计的这个算法很很巧妙,只有一个标量参数,也就是开始下标。而且,显然这个 st 是会被重复访问到的。比如 babccc 这个目标串,测试字典是 [a, b, ba, ab, c],其前缀 bab,对应字典前几个词,可以有多种方法,所以,显然 ccc 这个后缀会反复被搜索到,所以如果我们缓存了后,就会大量节省搜索时间。我可以用 st 作 key,缓存计算结果。1
2
3
4
5
6
7
8
9
10
11
12
13def wordBreak(self, s: str, wordDict: List[str]) -> bool:
n = len(s)
#注意这里
def dfs(st: int):
if st == n: return True
for w in wordDict:
if s.startswith(w, st):
res = dfs(st + len(w))
if res: return True
return False
return dfs(0)
Python 就是这么变态,只要在方法名前面加个修饰 @cache 就可以了,这个方法的值会自动调用 lru_cache。如此,就不会超时了(TLE)。加过缓存后,这个算法的时间复杂度就会大幅下降,目标串的每个 st 下标位置会缓存一个结果。然后就是对字典的遍历。
这道题目还可以用动态规划来解。因为我们发现,这个题目满足重叠子问题,最优子结构,无后效性三个条件。重叠子问题是,每个前缀后缀会被反复判定。最优子结构是,我们只需要回答能否被拆分,而不需要回答拆分的方法是什么。无后效性是,一个前后缀的拆分,跟已经切割掉的前后缀无关。
转移方程是这样的:f(n) = f(n - len(w)) && “w 是一个合法前后缀”
如果一个单词 w 是这个串的合法前后缀,那么去掉这个单词前后缀后,剩下的长度还是可以拆分,则说明整个串可以拆分,回到原初,一个空串显然是可以拆分的。基于上述分析,得到算法如下:1
2
3
4
5
6
7
8
9
10
11
12def wordBreak(self, s: str, wordDict: List[str]) -> bool:
n = len(s)
dp = [False] * (n + 1)
dp[0] = True
for i in range(1, n + 1):
for w in wordDict:
if dp[i] : break
if i - len(w) >= 0:
dp[i] = dp[i - len(w)] and s.endswith(w, 0, i)
return dp[n]
这个算法的时间复杂度是O(mn),m是字典长度,n 是目标串长度。空间复杂度是 O(n)。
— END —
这也是在一次字节的面试中遇到的题目,暂时也没有在 LC 找到题目的原型。题目是这样描述的:
给定一个二维矩阵,用于描述一处山地的地形,每个元素 a(i, j) 代表该座标位置的海拔高度,设想,现在下了一场足够大的雨后,将所有低洼处都填上水,请判断座标 (x,y) 的最高高度能否达到 h?(最高高度既可以是陆地,也可以是水面)举个例子:
给定地形为:1
2
3
43, 3, 3, 3
3, 1, 2, 3
3, 3, 3, 3
3, 3, 3, 3
在这个地形里,坐标(1,1)的高度是 1,坐标(1,2)的高度是 2,其余位置高度都是 3,我们假设矩阵外部全是深渊,现在低洼就是(1,1)和(1,2)两个格子。很显然,灌水后,会被填平,所有的坐标高度都将达到 3。(被水填平了)
decideHeight( x=1, y=1, h=3) 返回 True,坐标(1,1)位置能否达到高度 3?答案是 True。
decideHeight(x=1, y=2, h=4) 返回 False,坐标(1,2)位置能否达到高度 4?答案是 False。
其实,我在 LC 做过一个一维的接雨水的题目,给定的是一个截面图,然后用两侧的柱子高度来盛水,计算总共能接多少水。但是这个题目不一样,这个是判定水面的高度。受到一维题目的影响,我一直在往那个方向思考,无非就是把一维改为二维,先判断一个方向的盛水情况,再判定另一个方向。
但是我怎么也想不明白怎么做。后来面试官提示我第一点,我没必要计算出实际盛水的数量,做判断和计算具体值,是不一样的。其实这是非常重要的一个提示。因为只是做判定的话,就比具体算出来是多少要简单一点。
只考虑一个方向,两侧如果有高于给定高度的遮挡,则可以认为能够接水,否则就是不行。扩展到二维后,一个坐标点,需要四个方向来遮挡,才能盛水。所以给定一个坐标后,我们判定其四个方向,如果都高于给定坐标,则认为能接水。如果,并不高于给定坐标,那么是不是一定不行呢?未必,因为如果更远处有足够高的遮挡,也可以实现盛水。所以我们要将当前判断记为暂定,然后向远处延伸出去判定,直到找到封闭的遮挡或者触达边界。
于是,我写出了这样的算法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27def rainDrop(m: List[List[int]], a: int, b: int, h: int) -> bool:
row = len(m)
col = len(m[0])
visited = [[0] * col for i in range(row)]
def _rainDrop(x: int, y: int) -> bool:
visited[x][y] = 1
if m[x][y] >= h: return True
if x - 1 < 0: return False
if x + 1 >= row: return False
if y - 1 < 0: return False
if y + 1 >= col: return False
res = True
if visited[x-1][y] == 0:
res = res and _rainDrop(x - 1, y)
if visited[x+1][y] == 0:
res = res and _rainDrop(x + 1, y)
if visited[x][y-1] == 0:
res = res and _rainDrop(x, y - 1)
if visited[x][y+1] == 0:
res = res and _rainDrop(x, y + 1)
return res
return _rainDrop(a,b)
这个实现里,我用了一个递归算法,如果当前坐标的高度本身已经高于需要判定的高度,直接返回 True,否则就向四个方向延伸去判定是否能够遮挡。不过呢?为了避免重复,需要一个位图来记住已经访问过的坐标。这个算法,很显然,时空复杂度是 O(m×n),因为最坏情况会遍历每个格子一次,需要格子同等数量的位图来记录访问历史。
其实在面试当场,我是没能写对的,我没有能防止重复遍历,回来写出来运行后,发现我当时写的版本会死循环。遗憾。
等我写对后,我发现,这题目本质上是一个无向图的广度优先遍历,和一维接雨水毫无关系的一个算法类别。还真是,类似的表述会是完全不同的算法。所以还是要深入去掌握题目的条件和问题来思考算法,不能凭记忆和感觉解题。
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例 1:
输入:s = “3[a]2[bc]”
输出:“aaabcbc”示例 2:
输入:s = “3[a2[c]]”
输出:“accaccacc”示例 3:
输入:s = “2[abc]3[cd]ef”
输出:“abcabccdcdcdef”示例 4:
输入:s = “abc3[cd]xyz”
输出:“abccdcdcdxyz”
- 字符串解码 --> 传送门
今天做到这么一道题目,这个题目我一看,就想起了大学时候学习的编译原理,这个字符串解码,显然是“一个语言”,只不过这个语言的语法特别简单,只有字母,中括号和数字。我们要实现的就是,做一个这个“语言”的解释器,然后打印语句的结果。
既然是语言,我们就按照语言的方式来解决。这个语言里,只有四种 TOKEN(这是个专有术语),数字,左中括号,右中括号,字母,很容易划分 TOKEN,因为每种 TOKEN 的边界都是不同的字符。
语法非常简单,就是数字用于修饰一个字母串,中括号用于分割被修饰的字母串。只有唯一的操作,就是“打印”,有两种状态,“直接打印”,“重复打印”。于是我画了一个状态机:
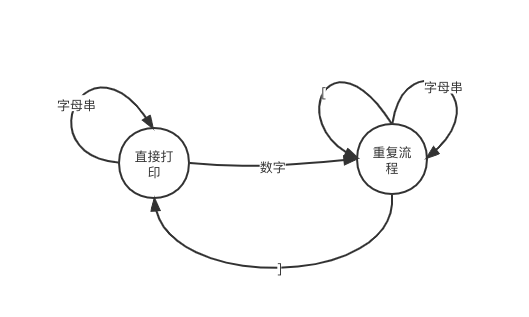
状态机
在初始状态下,遇到字母就直接打印,遇到数字,马上进入重复打印的流程,遇到右括号的时候,开始将遇到的模式重复打印。并退出重复打印的流程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def decodeString(self, s: str) -> str:
res = ''
count = 0
p = ''
state = 'print'
for c in s:
if state == 'print' and ord('a') <= ord(c) <= ord('z'):
res += c
elif ord('1') <= ord(c) <= ord('9'):
count = count * 10 + int(c)
elif c == '[':
state = 'start'
elif c == ']':
res += p * count
count, p = 0, ''
state = 'print'
elif state == 'start' and ord('a') <= ord(c) <= ord('z'):
p += c
return res
写出来一测,我才发现,原来括号是可以嵌套的。上面的代码对于嵌套的括号是没法正确处理的。并且通过编写这个代码,发现我识别的两个状态似乎也有点错误,这个语言太简单了,状态的切换也有点多于。
我发现,整个“语言”其实是一个递归的结构,可以表达成 “字母串 = 字母串 + 字母串 × 重复次数”,中括号其实就是字母串的分割边界。每遇到一个左括号,字母串的处理就深入一层,遇到一个右括号就跳出一层,只要用一个栈就可以轻松解决了。栈里要记录的东西,其实就是外层的前面一半字母串,以及内层需要重复的次数。这样,代码就改成了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def decodeString(self, s: str) -> str:
res = ''
count = 0
stack = []
for c in s:
if ord('a') <= ord(c) <= ord('z'):
res += c
elif ord('0') <= ord(c) <= ord('9'):
count = count * 10 + int(c)
elif c == '[':
stack.append((res, count))
res, count = '', 0
elif c == ']':
ctx_res, ctx_count = stack.pop()
res = ctx_res + res * ctx_count
return res
反倒更简洁了,我们需要求的是最外层的字母串,遇到左括号就压栈,遇到右括号,出栈的同时,做重复计算。栈里保留了当前字母串需要重复的次数。
这个算法的时间复杂度是O(n),空间复杂度也是O(n)。当然,到这里,想要写出这个算法的递归算法也是非常简单:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def decodeString(self, s: str) -> str:
def process() -> str:
nonlocal i
res = ''
count = 0
while i < len(s):
c = s[i]
i += 1
if ord('a') <= ord(c) <= ord('z'):
res += c
elif ord('0') <= ord(c) <= ord('9'):
count = count * 10 + int(c)
elif c == '[':
res += process() * count
count = 0
elif c == ']':
return res
return res
i = 0
return process()
– END –
题目的内容是,给定一个 m×n 的矩阵,搜索一个目标值 target,返回 bool 值。这个矩阵的特点是:
一开始我以为,这个题目太简单了,这个不是直接写就好了嘛,我只要遍历就好了啊,如果当前元素小于 target,就遍历右侧元素,如果遇到大于 target 的元素,就向下遍历,如果还是大于 target 就向左遍历,总是会找到的。
不过这个自然而然的想法,却是不对的。我写了三遍也没写对自己的这个想法。感觉自己太蠢了。然后我看了看题解,才发现竟然如此简单,可是我竟然连最简单的解法也没做出来。自己想了一个莫名其妙的遍历算法,既不是最简单的解法,也不是最巧妙的解法。
我想,可能是做了一定数量的题目后,我就失去了初心,总觉得自己有点积累了,可以一下找到最高效最简单的解了。
如果,我们抛弃一切技巧,按部就班暴力解题,怎么解呢?当然是从左到右,从上到下,逐一遍历,直到遍历完毕或者找到目标。这才是正确的遍历方法。也是最自然而然,基本没学过算法的人应该能想到的算法,也显然是一个正确的算法。
从题目的约束来看,这种暴力扫描法,复杂度 O(mn),最大也才 9 万的规模。可是我花了 2 个小时,也没想到这么去做。其实,解算法题,你的初心是把题目做对,做对后,再来讨论效率优化。想到了乔帮主的 stay foolish,才有点明白,为啥这时候就不能 stay foolish 呢?
如果,我们要提高算法的效率怎么做呢?题目的一个条件是,有序,搜索有序,自然而然就要想到二分查找,所以,我们在每个横行里,进行二分查找,那么在单行遍历,时间复杂度会降到 O(logn),总复杂度降到 O(mlogn),在大多数简单算法题给定的规模里,这个复杂度都足够应付了。
最后,如果我们还想优化,还有办法么?最后这个办法,可能是唯一不是普通人,随便就能想到的办法,如果一下点醒你,你会秒懂,但是没戳破就觉得真的想不到。我自己也没想明白。我怎么也想不到,如何才能按部就班想出这样的解题法。
其实有个数学家说过。如果你解不出一道题目,一定是你还没有充份利用好已知条件。好像认真看已知条件就一定能找到破解之法,但是没那么简单。比如这道题目,我们想出二分法,就是利用了有序,这个条件。但是,显然这题目给出了两个有序。从左到右,从上到下都是有序的。
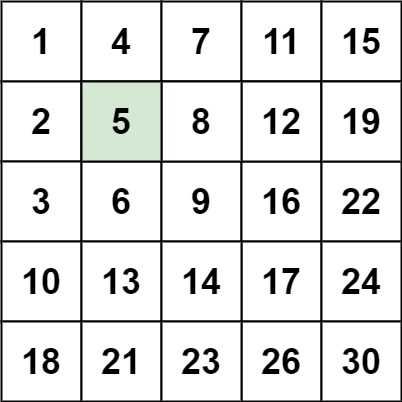
二维矩阵的例子
同时利用两个有序的方法,显然也是一个解法,就是没那么容易想到。而且,这是一个二维的矩阵。这个方法就是,我们遍历的时候,不一定从左上角开始遍历。而是从左下角或者右上角开始遍历。
程序员的思维定势是从左上角开始,当然也有一部分倒序的,那也会选择右下。但是能想到另外两个角,是要有怎样的经验和知识才能让你想到呢?这是我唯一的疑问。
以左下角为例,当你从左下角出发的时候,你发现,你上面的数字都比当前数字小,你右侧的数字都比当前大。右上角同理,其实左下角和右上角的数字,相当于所有数字的中间位置。
当前位置太小,就往右,太大就往上,循环往复,就会找到目标,或者结束遍历:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
m = len(matrix)
if m == 0: return False
n = len(matrix[0])
if n == 0: return False
x, y = m - 1, 0
while matrix[x][y] != target:
if matrix[x][y] > target:
if x - 1 >= 0:
x -= 1
else:
return False
else:
if y + 1 < n:
y += 1
else:
return False
return True
这个算法的时间复杂度是O(m+n),是已经分析过的算法里,复杂度最低的算法了。这题目说透了,就觉得太简单了。但是难点在于你就是想不到这里来。这题目给我一个最大的提醒,就是做题不要好高骛远,而是总要先想一个笨办法立于不败之地,再思考怎么优化,才是比较妥帖的做题态度。